
KI-gestützte Beschaffung von Awareness-Tools: Wie die KI die Shortlist schreibt
ChatGPT, Google AI Overviews und Perplexity liefern CISOs heute fertige Anbieter-Shortlists, bevor die eigentliche Marktrecherche beginnt. Eine Auswertung von 25 typischen Beschaffungs-Prompts zeigt: Welche Awareness-Anbieter empfohlen werden, hängt stärker von der gewählten Plattform und der Wortwahl der Frage ab als vom Funktionsumfang der Produkte. Worauf Sicherheitsverantwortliche bei der KI-gestützten Vorauswahl achten müssen und wo die Verzerrungen liegen, zeigt unser Autor.

Der typische Ablauf einer Security-Awareness-Beschaffung hat sich in den vergangenen 18 Monaten verschoben. Vor zwei Jahren startete der Informationssicherheitsbeauftragte mit einer Google-Suche und setzte sein Bild aus Fachpresse, Hersteller-Webseiten und Kollegenempfehlungen zusammen. Heute öffnet er ein Eingabefeld, tippt eine Frage ein und erhält eine zusammengefasste Antwort, in der bereits drei oder vier Anbieter namentlich genannt werden.
Die Shortlist entsteht nicht mehr am Ende der Recherche, sondern an ihrem Anfang. Wer eine KI-Antwort bekommt, sieht das Ergebnis, nicht aber den Weg dorthin: Welche Quellen wurden herangezogen? Welche Anbieter wurden berücksichtigt, welche fehlen?
Wie generative Suchmaschinen empfehlen
Die Untersuchung misst, welche Marken in den Antworten von ChatGPT, Google AI Overviews und Perplexity auftauchen, wenn Anwender im DACH-Raum nach Security-Awareness-Software suchen. Grundlage sind 25 typische Kaufprompts auf drei Plattformen, mehrfach ausgeführt und über die Analyseplattform Profound ausgewertet.
Insgesamt tauchten 317 Anbieter in den Antworten auf, hinzukommen 4.724 ausgewertete Quellenverweise. Die folgenden Befunde konzentrieren sich auf das, was für den Beschaffungsprozess strukturell relevant ist: wo sich die Plattformen unterscheiden, wo die Wortwahl der Frage die Ergebnisse verzerrt und welche Quellen die Antworten tragen.
Eine generative Suchmaschine beantwortet eine Frage nicht, indem sie einen Datensatz aus einem Regal zieht. Sie zerlegt die Anfrage in mehrere Teilanfragen, sucht für jede passende Quellen, fasst die Treffer zu einer Antwort zusammen und bringt die genannten Marken in eine Reihenfolge. Diese internen Teilanfragen heißen Fanout-Queries. In den Messungen löste ein einzelner Prompt auf ChatGPT im Schnitt 1,71 interne Suchen aus, auf Perplexity 1,14. Eine Marke, die in einer Fragefamilie wie „Security Awareness Training für deutsche Unternehmen“ erscheint, taucht mit hoher Wahrscheinlichkeit auch bei „DSGVO-konforme Awareness-Lösung“ auf, weil das System denselben Quellenpool durchsucht. Gemessen wird also weniger die Sichtbarkeit bei einer exakten
Formulierung als die strukturelle Präsenz innerhalb eines Themenclusters.
Drei Plattformen, drei verschiedene Antworten
Auffällig ist vor allem die Plattformabhängigkeit der Empfehlungen. SoSafe, Spitzenreiter im Gesamtranking mit einem Visibility Score von 63,6 Prozent, kommt auf Google AI Overviews auf 84,8 Prozent. Auf ChatGPT erreicht derselbe Anbieter im gleichen Messdurchlauf nur noch 54,3 Prozent und teilt sich die Spitze mit KnowBe4. Auf Perplexity sind es 51,5 Prozent. Das sind rund 30 Prozentpunkte Differenz zwischen zwei Antwortsystemen, in derselben Sprache, in derselben Region.
Die Ursache liegt in den Quellen, aus denen die Plattformen ihre Antworten zusammensetzen. ChatGPT greift überproportional auf englischsprachige Autoritätsquellen zurück, vor allem Wikipedia, Gartner und Review-Portale wie G2.
Abbildung 1: Visibility Score der zehn meistgenannten Awareness-Anbieter über alle drei Antwortsysteme hinweg (ChatGPT, Google AI Overviews, Perplexity, April 2026). Der Wert gibt an, in welchem Anteil der 25 Beschaffungs-Prompts die jeweilige Marke in der KI-Antwort genannt wurde.
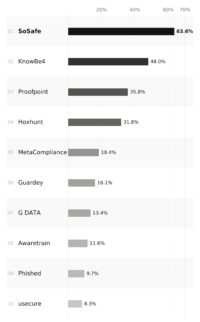
Gartner erscheint in der Messung mit 41 von insgesamt 44 Quellenverweisen fast ausschließlich auf ChatGPT. Google AI Overviews und Perplexity stützen ihre Antworten auf eine breitere Mischung aus deutschsprachiger Fachpresse, Branchenportalen und Vergleichsseiten. Die größte Plattform-Differenz bei einer einzelnen Marke betrifft MetaCompliance: 37,1 Prozent Visibility Score auf ChatGPT, 3 Prozent auf Perplexity – eine Spreizung von 34 Prozentpunkten beim selben Anbieter. Eine Plattform allein liefert also kein Marktbild, sondern nur die Sicht jener Quellen, die sie bevorzugt zitiert.
Die Wortwahl entscheidet
Eine zweite, weniger sichtbare Verzerrung steckt in der Wortwahl selbst. Für die Untersuchung wurde dieselbe Anbietergruppe für fünf Kaufmomente gemessen: Awareness-Training, Phishing-Simulation, NIS-2 und Compliance, Human Risk Management, Wettbewerbsvergleich.
Die Reihenfolge der Anbieter verschiebt sich von Kaufmoment zu Kaufmoment so deutlich, dass ein Beschaffungsverantwortlicher mit einem einzigen Prompt einen verzerrten Ausschnitt seiner Anbieterlandschaft erhält. KnowBe4 belegt im Gesamtranking Rang 2 mit 48 Prozent
Abbildung 2: Visibility Score nach Kaufmoment: Je nach Formulierung der Beschaffungsfrage verschiebt sich die Anbieter-Reihenfolge deutlich.

Sobald die Frage den Begriff „Human Risk Management“ enthält, fällt der Wert auf 26,6 Prozent und damit auf etwa die Hälfte. Mimecast, im Gesamtranking nur Rang 14 mit 6,3 Prozent, springt in derselben Kategorie auf Rang 3 mit 34,6 Prozent. Eine Frage der Wortwahl, nicht des Funktionsumfangs.
In der Kategorie Phishing-Simulation dreht sich das Bild noch einmal. Hier landet SoSafe, sonst Spitzenreiter, auf Rang 4 mit 41,6 Prozent. An der Spitze steht Proofpoint mit 53,1 Prozent, dahinter folgen KnowBe4 und Hoxhunt. In den Quellen ist der Begriff historisch eng an die E-Mail-Security-Tradition gekoppelt. Wer also nur „Phishing-Simulation“ eingibt, erhält eine andere Anbietergruppe als jemand, der mit „DSGVO-konformes Awareness-Training“ startet, obwohl beide ähnliche Produkte suchen.
Bei NIS-2-bezogenen Fragen sinken die Visibility Scores aller Anbieter spürbar, selbst der Kategoriesieger SoSafe kommt nur auf 48 Prozent. Stattdessen erscheinen Institutionen häufiger: TÜV, IHK, BSI, Fraunhofer. Generative Antwortsysteme spiegeln damit, was in der frei zugänglichen NIS-2-Berichterstattung dominiert.
Quellen prägen die Antwort
Über alle drei Plattformen hinweg kamen 4.724 Quellenverweise aus 695 Domains zusammen. Klassische Earned Media machen rund 8,2 Prozent aus, soziale Quellen wie Reddit und YouTube 7,3 Prozent, Institutionen wie BSI, IHK, TÜV oder Gartner 4,2 Prozent. Der größte Block, mehr als drei Viertel, entfällt auf Hersteller-Hubs und kleinere Fachportale. Neun der fünfzehn am häufigsten zitierten Domains sind Webseiten der Anbieter selbst, darunter sosafe-awareness.com, guardey.com, proofpoint.com, knowbe4.com und gdata.de – keine Produktseiten, sondern Content-Hubs mit Ratgebern, Vergleichsartikeln und Glossaren. Solche Hubs liefern der KI die Inhalte, die direkt zitiert werden, und gleichzeitig das Rohmaterial, aus dem das Antwortsystem die Reihenfolge der Wettbewerber ableitet.
Abbildung 3: Die fünfzehn am häufigsten zitierten Domains in den KI-Antworten zu Awareness-Software: Neun davon sind Content-Hubs der Anbieter selbst, angeführt von sosafe-awareness.com (8,81 Prozent) und guardey.com (4,14 Prozent). Unabhängige Quellen wie security-insider.de (1,64 Prozent), Gartner (1,31 Prozent) oder Wikipedia (1,25 Prozent) liegen deutlich dahinter. (Bild: Recon Rise / Profound)
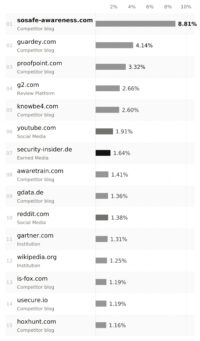
Besonders deutlich wird der Effekt bei Guardey. Die Marke steht im Gesamtranking nur auf Rang 6 mit 16,1 Prozent, ihre Domain liegt bei den zitierten Quellen jedoch auf Platz 2 mit 182 Verweisen – mehr als Proofpoint, KnowBe4 oder Hoxhunt. Auf Perplexity rückt Guardey dadurch auf Rang 4 mit 24,2 Prozent vor. Auf ChatGPT fällt die Marke dagegen auf Rang 10 mit 7,3 Prozent zurück.
Eine KI-Empfehlung ist damit keine unabhängige Bewertung, sondern eine algorithmische Verdichtung dessen, was im öffentlichen Web zu einer Kategorie geschrieben wird. Sie spiegelt die Sichtbarkeit von Marketingarbeit, Fachpresseplatzierungen und Hub-Strategien, nicht die Qualität der Produkte.
Checkliste KI-gestützte Marktrecherche für Awarenessoftware
Die folgenden sieben Schritte unterstützen Informationssicherheitsverantwortliche bei einer strukturierten KI-gestützten Vorrecherche, bevor die eigentliche Anbieteransprache beginnt.
- mindestens drei Antwortsysteme parallel verwenden, zum Beispiel ChatGPT, Google AI Overviews und Perplexity, und die Anbieterlisten miteinander abgleichen
- mindestens drei Begriffsvarianten der Recherchefrage stellen, etwa funktional, compliance-orientiert, risikoorientiert
- Antworten auf zitierte Quellen prüfen und die Quellenmischung bewerten: Hersteller-Hubs, Fachpresse, Institutionen, Vergleichsportale
- Anbieter, die nur auf einer einzigen Plattform sichtbar sind, separat notieren und nicht voreilig ausschließen
- branchenspezifische Anbieter, regionale Spezialisten und kleinere Plattformen aktiv ergänzen, etwa über Verbände oder Peer-Netzwerke
- eine eigene Bewertungsmatrix erstellen, in der DSGVO-Konformität, EU-Hosting, Sprachabdeckung, Audit-Reporting und Schnittstellen abgebildet sind
- die finale Shortlist erst nach Abschluss dieser Schritte festlegen, nicht direkt aus der ersten Antwort eines einzelnen Systems übernehmen
Bausteine einer belastbaren Vorrecherche
Aus den Beobachtungen lässt sich eine Methodik für Informationssicherheitsverantwortliche ableiten, die KI-gestützte Recherche nutzen wollen, ohne sich auf eine einzelne Antwort zu verlassen.
Erstens braucht es mehrere Plattformen parallel – eine Anfrage an ein einzelnes System reicht nicht. Sinnvoll ist es, ChatGPT, Google AI Overviews und Perplexity dieselbe Frage zu stellen und die genannten Anbieter anschließend abzugleichen. Marken, die nur auf einer Plattform auftauchen, sind nicht zwingend schwächer, sondern oft nur stärker in deren Quellen verankert.
Zweitens sind mehrere Formulierungsvarianten derselben Frage nötig: eine fachlich-funktionale mit „Awareness-Training“, eine compliance-orientierte mit Bezug zu NIS-2 oder zur Datenschutz-Grundverordnung (DSGVO), und eine, die das Risikomanagement betont, etwa mit „Human Risk Management“ oder „Phishing-Simulation“. Erst die Schnittmenge ergibt eine belastbare Shortlist.
Drittens lohnt ein Blick auf die zitierten Quellen. Dominieren Hersteller-Hubs die Liste, ist die Antwort marketinggeprägt. Tauchen dort BSI, TÜV oder spezialisierte Fachredaktionen auf, ist sie näher am unabhängigen Diskurs.
Was die KI als Empfehlung ausgibt, ist eine Vorauswahl entlang der Quellenlandschaft, nicht entlang der funktionalen Anforderungen des eigenen Hauses. Branchenspezifische Anbieter und regionale Spezialisten können systematisch unterrepräsentiert sein. Es lohnt sich, klassische Quellen wie Verbands- oder Peer-Empfehlungen zu ergänzen. Ob ein Tool die relevanten Sprachvarianten unterstützt, sich an bestehende Identity-Provider anbindet und die Reporting-Funktionen für die eigene Audit-Logik ausreichen, lässt sich erst in einer eigenen Bewertungsmatrix klären.
Anbieterseite: Sichtbarkeit als Wettbewerbsfaktor
Die Verlagerung der Marktrecherche in generative Antwortsysteme verändert auch, wie sich Anbieter im Markt positionieren müssen. Wer in den Quellen, die diese Systeme heranziehen, nicht ausreichend präsent ist, verliert Sichtbarkeit in der Anbahnungsphase – lange bevor ein Vertriebsgespräch zustande kommt. Etablierte deutsche Spezialisten wie IS-FOX, Hornetsecurity oder secunet erscheinen auf den großen Antwortsystemen messbar schwächer, als ihre Marktposition im DACH-Raum vermuten ließe. Auf Google AI Overviews sind sie zwar präsent, auf ChatGPT und Perplexity dagegen kaum.
Fazit
Security-Awareness-Software ist ein Markt, in dem Vertrauen, Datenschutz, Sprachqualität und kulturelle Passung über den Schulungserfolg entscheiden. Diese Faktoren lassen sich in keiner KI-Antwort erschöpfend abbilden. Sie werden erst in der konkreten Demo, im Test mit einer Pilotgruppe und in der Reaktion der Belegschaft sichtbar. Die KI verkürzt den Weg zur Vorauswahl, ersetzt ihn aber nicht.
Die eigentliche Auswahl bleibt eine Aufgabe des Informationssicherheitsbeauftragten – mit denselben kritischen Fragen, die er einer Sicherheitsarchitektur stellen würde. Auch eine KI-Empfehlung gehört auf den Prüfstand, gerade wenn sie glatt klingt.

Luke Kotlin ist Co-Founder und Head of AI Visibility bei Recon Rise in Düsseldorf. Recon Rise ist auf Generative Engine Optimization spezialisiert und begleitet B2B- und B2C-Marken bei ihrer Sichtbarkeit in generativen Antwortsystemen.
Methodik der Auswertung
Datenbasis des Beitrags ist der „AI Visibility Index DACH 2026 – Human Risk Management“ der Düsseldorfer Agentur Recon Rise. Gemessen wurde im April 2026 mit der Analyseplattform Profound.
- Plattformen: ChatGPT, Google AI Overviews, Perplexity
- Region/Sprache: Deutschland, deutschsprachige Prompts
- Prompts: 25 typische Beschaffungsfragen aus fünf Kaufmomenten (Security-Awareness-Training, Phishing-Simulation, NIS-2 und Compliance, Human Risk Management, Wettbewerbsvergleich)
- Ausführung: jeder Prompt mehrfach pro Plattform
- Erfasst: 317 unterschiedliche Anbieter in den Antworten, 4.724 Quellenverweise aus 695 Domains
Drei Kennzahlen:
Visibility Score: Anteil der Prompts, in deren Antwort eine Marke genannt wird (63 Prozent heißt: in fast zwei von drei Anfragen präsent).
Average Position: durchschnittliche Position der Marke innerhalb der KI-Antwort.
Citations: Quellen, auf die das Antwortsystem zur Beantwortung zurückgreift.
Die Auswertung erfasst die Sichtbarkeit zu einem definierten Zeitpunkt. Da generative Antwortsysteme ihre Modelle und Quellenlogik laufend anpassen, sind die Werte als Momentaufnahme zu verstehen.
Newsletter Abonnieren
Abonnieren Sie jetzt IT-SICHERHEIT News und erhalten Sie alle 14 Tage aktuelle News, Fachbeiträge, exklusive Einladungen zu kostenlosen Webinaren und hilfreiche Downloads.


